


In the recent weeks, we’ve directed our focus towards intensive work on orchestration possibilities. Additionally, we’ve continued our experiments with the microservice architecture and keep improving developer experience of the framework extensibility. For the full list of changes that have been made in the last releases, you can check our changelog.
Kubernetes Orchestration

As Shopsys Framework runs naturally in Docker containers, we plan to deploy it to the production server using Kubernetes. This is an orchestration tool that is suitable for running the containerized application in the cloud solutions like AWS, Google Cloud or Azure where it is ready for scaling easily when you need it. You can read more about it in the “Introduction to Kubernetes” article in our documentation.
We have never worked with Kubernetes orchestration before but we gained some experience when we tweaked Jenkins CI to do some basic orchestration in the past, even without Kubernetes. Our developer, Matouš Czerner, described all the tricks we used in his “Jak na Jenkins CI pro aplikaci v Dockeru” presentation (in Czech) on “Friends of PHP meetup” in Brno on 18.4.2018.

Now, we have taken a huge step towards making Shopsys Framework ready for usage in cloud solutions by implementing Kubernetes for our continuous integration on Jenkins. You can read more about that in the “Continuous Integration Using Kubernetes” article in the docs. Because we currently keep our infrastructure as code, you can see all the changes that have been made in the source code in pull request #393.
Elasticsearch Data Export in Microservice
In the last Release Highlights article, we described the development of our first microservice. Since then, we’ve created yet another microservice that is responsible for exporting products’ data into Elasticsearch. As a result, the framework is now completely independent of Elasticsearch and the whole communication with the search engine is done via microservices.
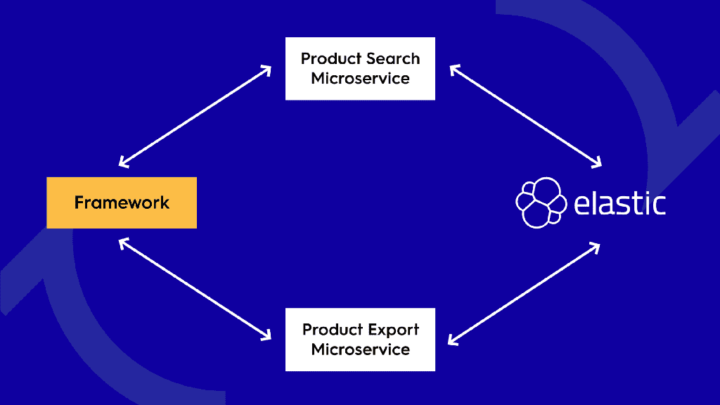
The great advantage of this approach is that the whole functionality is now ready to be developed, deployed, and scaled separately. Besides that, there were several more reasons for implementing the data export in the new standalone microservice. It fits the single responsibility principle that is very important with the microservices approach, and product export has now no impact on product search performance whatsoever. Also, as we are still learning how to use the microservices architecture, we thought it vital to implement more than one in order to gain the real-life experience. To explore technical details about the implementation, see pull request #429.
Furthermore, the microservices are built as docker images. This is the next step for microservices independence which makes it much easier to install and use them. You can see the actual changes in the source code in pull request #430.
Better developer experience
For extending the framework (e.g. adding a new attribute to an entity), we use the PHP class inheritance. In order to ease the development as much as possible, we prepared empty extended classes in the project-base for the most commonly edited entities (such as Product, Customer, Transport, Payment, Order). The entity itself is not the only class that needs to be extended; there are also data objects, forms, factory classes, etc., so the developer does not need to create whole new classes anymore and can modify the prepared ones instead.
As a result, it is now much easier to extend an entity, effectively reducing the amount of the code a developer has to write from 190 to 30 lines. This is according to changes which you can find in the cookbook for adding a new attribute to an entity. You can see the changes in the source code in pull request #409.
All our developers who use Docker on Mac are a lot happier as well because we optimized the Docker settings and improved the stability of the files synchronization between the host machine and container in pull request #468.
Performance improvements
Performance is a topic that we work on continuously. Recently, we improved an application’s performance by approximately 8% by fine-tuning the Postgres configuration. You can see the actual changes in the configuration in pull request #444.
Čtěte také



